Collecting Twitter data using Twitter API
Get your Twitter Developer Account
First, you have to set up a Twitter Developer Account. Go to https://developer.twitter.com/en/docs/twitter-api/getting-started/getting-access-to-the-twitter-api and sign up.
Note: Use at your own risk. Be ethical about user data.
Required libraries
library(rtweet)
library(dplyr)
library(ggplot2)
library(tidytext)
library(stringr)
Create a Twitter App and generate necessary keys and tokens
In order to create an app, you need to log in to Twitter Developer Account and click on “+Create App”.
Afterwards you need to generate the necessary keys/tokens to access the official Twitter API (click on regenerate/yellow).


I would advice to store those in your R script. Note: These are fake example values. Please replace those with your own keys.
api_key <- "yourownkey"
api_secret_key <- "xyz123456"
access_token <- "yourowntoken"
access_token_secret <- "xyz123456P"
Authenticate via web browser
Note: The name of the app is an example, exchange for your own app name.
create_token(
app = "Example_app",
consumer_key = api_key,
consumer_secret = api_secret_key,
access_token = access_token,
access_secret = access_token_secret)
Start the madness
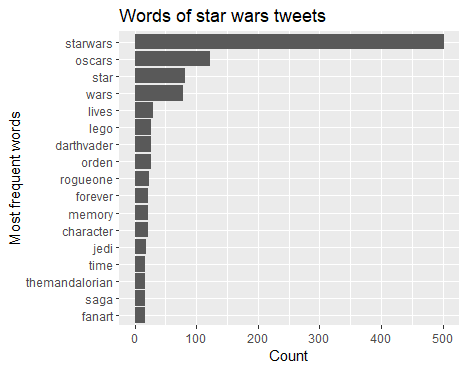
Here the collection process starts. We want to collect n= 500 tweets including the hashtag #starwars
tweets_starwars <- search_tweets(q="#starwars",
n = 500)
View the first 5 rows of the text in the dataframe
head(tweets_starwars$text, n = 5)
Count the most frequently used words and plot them (using ggplot2)
tweets_starwars_only_text <- tweets_starwars %>%
dplyr::select(c(5)) %>% # select the "text" column
unnest_tokens(output = word, input = text)%>% # tokenization
anti_join(stop_words)%>% # remove stopwords
filter(!str_detect(word, "[:punct:]|[:digit:]")) #remove punctuation and numbers
tweets_starwars_only_text %>%
count(word, sort = TRUE) %>%
mutate(word = reorder(word,n)) %>%
na.omit() %>%
top_n(15) %>% # take top 15 words
ggplot(aes(x = word,y = n)) +
geom_col() +
coord_flip() +
labs(x = "Most frequent words",
y = "Count",
title = "Words of star wars tweets ")