Sentiment analysis with Amazon reviews
In this little tutorial I will show you how to gahter review data from Amazon and how to implement a simple sentiment analysis using the BING lexicon. The code for scraping data is a modified rewrite (I included the date as another variable) from Martin Chan (https://martinctc.github.io/blog/)
Note: Use at your own risk. Be ethical about user data.
Required libraries
library(tidyverse)
library(dplyr)
library(tidytext)
library(stringr)
library(tm)
library(wordcloud)
library(rvest)
library(reshape2)
library(SnowballC)
Scraping function
scrape_amazon <- function(ASIN, page_num){
url_reviews <- paste0("https://www.amazon.co.uk/product-reviews/",ASIN,"/?pageNumber=",page_num)
doc <- read_html(url_reviews)
# Review Title
doc %>%
html_nodes("[class='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold']") %>%
html_text() -> review_title
# Review Text
doc %>%
html_nodes("[class='a-size-base review-text review-text-content']") %>%
html_text() -> review_text
# Number of stars in review
doc %>%
html_nodes("[data-hook='review-star-rating']") %>%
html_text() -> review_star
# Date
doc %>%
html_nodes("[data-hook='review-date']") %>%
html_text() -> review_date
tibble(review_title,
review_text,
review_star,
review_date,
page = page_num) %>% return()}
Define ASIN and number of pages
Since I am a big StarWars fan, I want to take a look at the reviews of the movie “a new hope” The movie got more than 1.000 reviews. But first you have to specify the ASIN. Its the Amazon Identification number and you can find it in the URL. Next, we specify the how many review pages we want to scrape. In this example just set the number to 15.
ASIN <- "B00VIZDW3S"
page_range <- 1:15

Scrape the actual data
In the next step we scrape the reviews from the pages 1-15. The code does include a break-system to avoid bot detection
match_key <- tibble(n = page_range,
key = sample(page_range,length(page_range)))
lapply(page_range, function(i){
j <- match_key[match_key$n==i,]$key
message("Getting page ",i, " of ",length(page_range), "; Actual: page ",j)
Sys.sleep(3)
if((i %% 3) == 0){
message("Taking a break...")
Sys.sleep(2)
}
scrape_amazon(ASIN = ASIN, page_num = j)
}) -> output_list
Transform data into a dataframe
Starwars_newHope<- dplyr::bind_rows(output_list)
Calculate/visualize the (mean) star rating
Starwars_newHope<- Starwars_newHope %>%
mutate_at("review_star", str_replace, " out of 5 stars", "")
Starwars_newHope_starrating <- as.numeric(unlist(Starwars_newHope$review_star))
ggplot() + aes(Starwars_newHope_starrating)+ geom_histogram(binwidth=1, colour="blue", fill="blue")
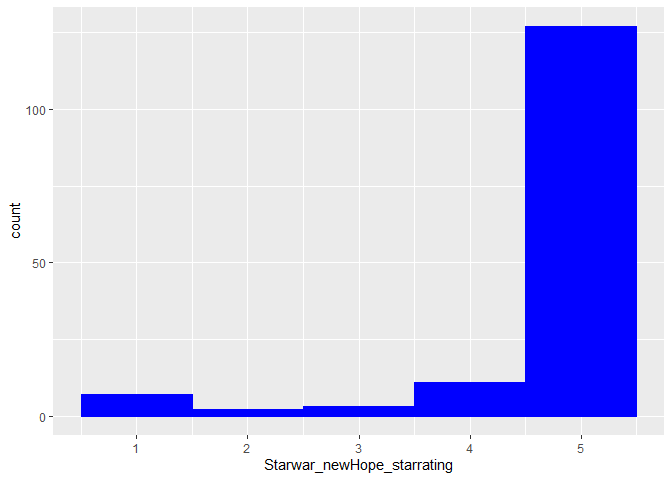
# The mean rating out of 5 possible stars
mean(Starwars_newHope_starrating, na.rm=TRUE)
## [1] 4.66
In general the movie was perceived very positively and viewers gave the movie mostly 5 out of 5 stars (mean = 4.66)
Data prep for sentiment analysis
Data preparation includes removing stopword, remove spaces, numbers, punctuation etc. (tm package), tokenization
Review_Starwars_newHope <- Starwars_newHope %>% dplyr::select(review_text)
Review_Starwars_newHope$review_text <- Review_Starwars_newHope$review_text%>%
tolower() %>%
removeNumbers()%>%
removePunctuation()%>%
stripWhitespace()
Review_Starwars_newHope <- Review_Starwars_newHope %>%
unnest_tokens(output = "word", input = "review_text")%>%
anti_join(tidytext::stop_words, by = "word")
# In order to stem the data use SNOWBALLC
# Review_Starwars_newHope_stem <- Review_Starwars_newHope %>% mutate(word = wordStem(word))
Sentiment analysis using the bing lexicon
Review_Starwars_newHope %>%
inner_join(get_sentiments("bing")) %>%
dplyr::count(word, sentiment, sort = TRUE) %>%
filter(n > 4) %>%
mutate(word = reorder(word, n)) %>%
mutate(percent = round(n/sum(n), 3)) %>%
ggplot(aes(x = word, y = percent, fill = sentiment, label = percent)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
geom_text(aes(y = 0.7*percent)) +
labs(title = "Starwars-a new hope- Word Polarity (bing)") +
coord_flip() +
theme_bw() +
theme(plot.title = element_text(hjust = 0.5))
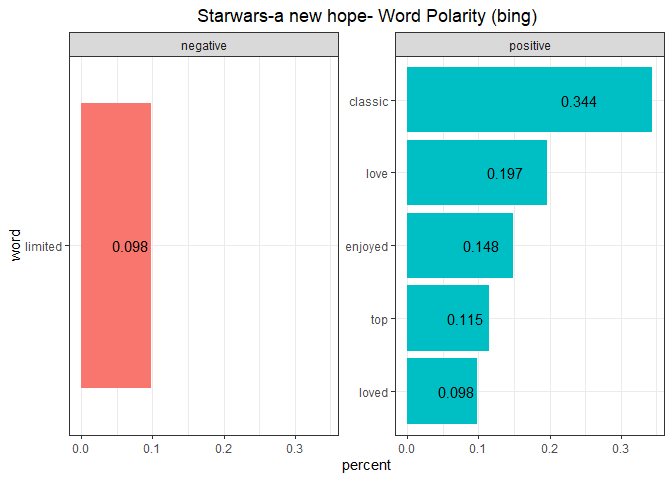
There is only one negative word occurring more than >4 times. Other than that the sentiment is dominated by positive words like ‘love’ or ‘excellent’.
Calculating the overall sentiment using afinn lexicon
Sentiment_Starwars_NewHope <- Review_Starwars_newHope %>%
inner_join(get_sentiments("afinn"))
mean(Sentiment_Starwars_NewHope$value) # 1.18
The mean sentiment of the movie reviews are rather positive (overall sentiment score = 1.18)
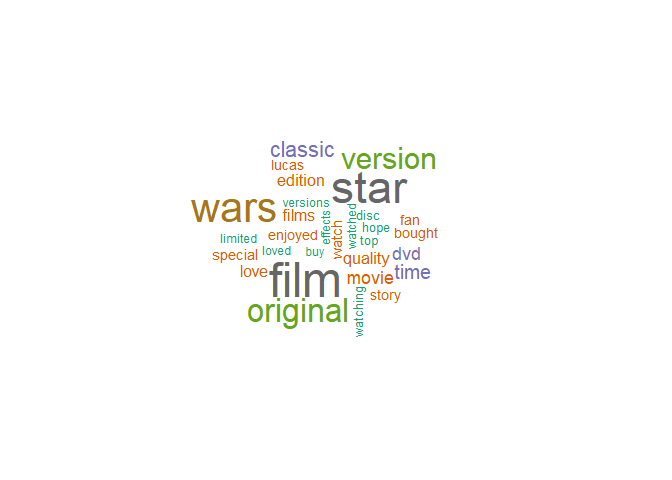
Creating a wordcloud with the most often used words
word.freq.table<- Review_Starwars_newHope %>%
dplyr::count(word)%>%
filter(n>5) %>%
with(wordcloud(word, n,
scale = c(3,0.5),
colors = brewer.pal(8, "Dark2")))
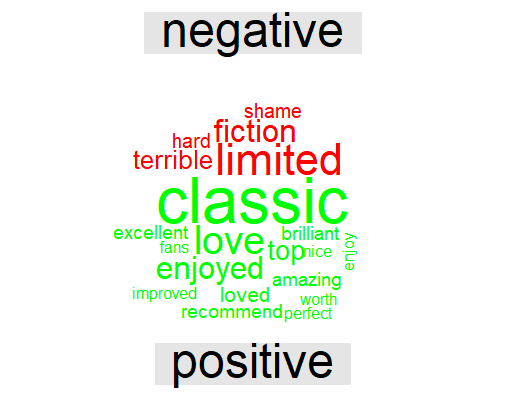
Create a wordcloud taking sentiment polarity under account
Review_Starwars_newHope %>%
inner_join(get_sentiments("bing")) %>%
dplyr::count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("red", "green"),
max.words = 20)